Summarizer
- Dapatkan link
- X
- Aplikasi Lainnya
AI News Summarizer Spend less time reading news
INTRODUCTIONS
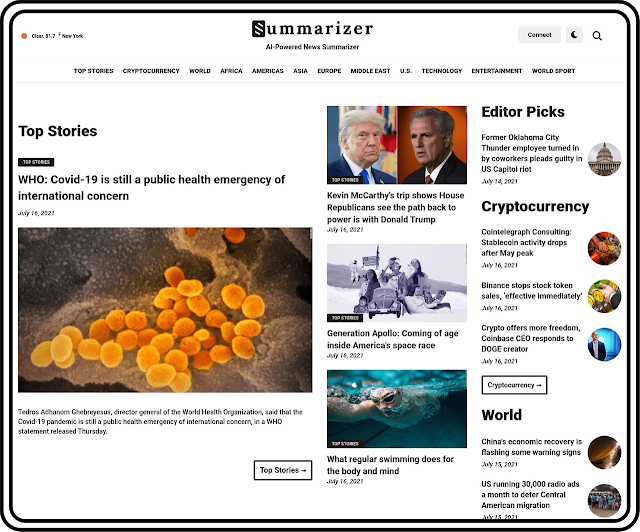
What is SUMMARIZER ?
AI News Summarizer - a fully automated newspaper.
Summarizer aims to make your daily news shorter by utilizing AI.
Its bots crawl the web for news, summarize them, and then sort them into categories.
It is a fully automated newspaper.
Summarizer aims to make your daily news shorter by utilizing AI.
Its bots crawl the web for news, summarize them, and then sort them into categories.
Summarizer is exclusive to $SMR holders.
You won't have to pay anything, just simply holding
$SMR to read Summarizer contents.
At any time, you decide to stop reading Summarizer, you can
just sell your $SMR back to the market.
Run but bots
But for the human
Summarizer is run by a family of bots .
There are crawler-bot, summa-bot,
editor-bot, delivery-bot, optimizing-bot,
repairing-bot, etc.
AI-Powered
Making your daily news shorter by
utilizing AI
We use TextRank with optimizations on
the similarity function for text
summarization.
Elegant, and fast
Optimized UX & UI
Come with dark & light modes, stripped
all the unnecessary elements, optimized
for speed. Articles on Summarizer
normally take less than 1s to be fully
loaded.
Telegram
You love Telegram, right?
Good news! There is a bot of the
Summarizer bots family, who is
specialized in delivery Summarizer
content to Telegram
No payment hassle
Cause there is no payment
There is no subscription fee, you simply
hold $SMR to read Summarizer. At any
time, you decide to stop reading
Summarizer, you can sell your $SMR
back to the market.
Privacy
No tracker on Summarizer
Unlike almost any other news website,
Summarizer doesn't have any piece of
code to track your identity and
behaviors.
Algorithm
TextRank is an unsupervised algorithm for the automated summarization of texts that can also be
used to obtain the most important keywords in a document. It was introduced by Rada Mihalcea
and Paul Tarau
The algorithm applies a variation of PageRank over a graph constructed specifically for the task of
summarization. This produces a ranking of the elements in the graph: the most important
elements are the ones that better describe the text. This approach allows TextRank to build
summaries without the need of a training corpus or labeling and allows the use of the algorithm
with different languages.
For the task of automated summarization, TextRank models any document as a graph using
sentences as nodes . A function to compute the similarity of sentences is needed to build edges in
between. This function is used to weight the graph edges, the higher the similarity between
sentences the more important the edge between them will be in the graph. In the domain of a
Random Walker, as used frequently in PageRank , we can say that we are more likely to go from
one sentence to another if they are very similar.
TextRank determines the relation of similarity between two sentences based on the content that
both share. This overlap is calculated simply as the number of common lexical tokens between
them, divided by the lenght of each to avoid promoting long sentences. The function featured in
the original algorithm can be formalized as:
Definition 1. Given Si
, Sj two sentences represented by a set of n words that in Si are represented
as Si = wi
, wi
, ..., wi
. The similarity function for Si, Sj can be defined as:
The result of this process is a dense graph representing the document. From this graph, PageRank
is used to compute the importance of each vertex. The most significative sentences are selected
and presented in the same order as they appear in the document as the summary.
These ideas are based in changing the way in which distances between sentences are computed
to weight the edges of the graph used for PageRank. These similarity measures are orthogonal to
the TextRank model, thus they can be easily integrated into the algorithm. We found some of these
variations to produce significative improvements over the original algorithm.
Longest Common Substring From two sentences we identify the longest common substring and
report the similarity to be its length
Cosine Distance The cosine similarity is a metric widely used to compare texts represented as
vectors. We used a classical TF-IDF model to represent the documents as vectors and computed
the cosine between vectors as a measure of similarity. Since the vectors are defined to be positive,
the cosine results in values in the range [0,1] where a value of 1 represents identical vectors and 0
represents orthogonal vectors .
BM25 BM25 / Okapi-BM25 is a ranking function widely used as the state of the art for Information
Retrieval tasks. BM25 is a variation of the TF-IDF model using a probabilistic model .
Definition 2. Given two sentences R, S, BM25 is defined as:
where k and b are parameters. We used k = 1.2 and b = 0.75. avgDL is the average length of the
sentences in our collection.
This function definition implies that if a word appears in more than half the documents of the
collection, it will have a negative value. Since this can cause problems in the next stage of the
algorithm, we used the following correction formula:
where ε takes a value between 0.5 and 0.30 and avgIDF is the average IDF for all terms. Other
corrective strategies were also tested, setting ε = 0 and using simpler modifications of the classic
IDF formula.
We also used BM25+, a variation of BM25 that changes the way long docu- ments are penalized .
Evaluation
We tested LCS, Cosine Sim, BM25 and BM25+ as different ways to weight the edges for the
TextRank graph. The best results were obtained using BM25 and BM25+ with the corrective
formula shown in equation 3. We achieved
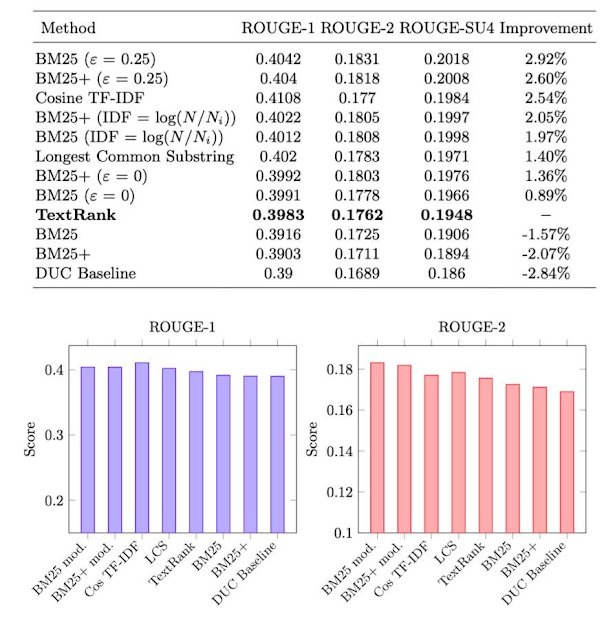
an improvement of 2.92% above the original TextRank result using BM25 and ε = 0.25. The
following chart shows the results obtained for the different variations we proposed.
The result of Cosine Similarity was also satisfactory with a 2.54% improvement over the original
method. The LCS variation also performed better than the original TextRank algorithm with 1.40%
total improvement.
The performance in time was also improved. We could process the 567 documents from the
DUC2002 database in 84% of the time needed in the original version.
I have placed a link for more information below
https://t.me/SummarizerOfficial
https://twitter.com/SummarizerC
https://medium.com/@summarizer
https://medium.com/@summarizer
https://www.facebook.com/Summarizer-100158469034381/
https://www.reddit.com/user/Summarizer_Official
Author
Forum Username: EEN 400
Forum Profile Link: https://bitcointalk.org/index.php?action=profile;u=3120889
Telegram Username: @EEN400
ETH Wallet Address: 0x7C22CE25152B07Db23B32FC8C36711be90d86181
- Dapatkan link
- X
- Aplikasi Lainnya



Komentar
Posting Komentar